it is not symmetric and does not satisfy triangle inequality
it is better to use “KL divergence” instead of ”KL distance”
H(p)+D(p∥q) bits needed to encode p using q
Explain Mutual Information (formula expected too).
I(X,Y)=D(p(x,y)∥p(x)p(y))
how much our knowledge of Y contributes (on average) to easing the prediction of X
by how many bits the knowledge of Y lowers the entropy H(X)
I(X,Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
how p(x,y) deviates from p(x)p(y)
I(X,Y)=∑x∈Ω∑y∈Ψp(x,y)log2p(x)p(y)p(x,y)
measured in bits
I(X,X)=H(X)
I(X,Y)=I(Y,X)
I(X,Y)≥0
Language models, the noisy channel model
Explain the notion of The Noisy Channel.
idea: we have the noisy output, we want to “predict” the original input
we want to find such an original input that p(original∣noisy) is maximum
Bayes formula: p(A∣B)=p(B)p(B∣A)p(A)
The Golden Rule: Abest=argmaxAp(B∣A)p(A)
if used for speech recognition
p(B∣A) … acoustic model
p(A) … language model
Explain the notion of the n-gram language model.
it would be impractical to compute the probability of a sequence of words as p(W)=p(w1,w2,…,wn)=p(w1)⋅p(w2∣w1)⋅…⋅p(wn∣w1,w2,…,wn−1)
there would be too many parameters in the model
in an n-gram language model, we only remember n−1 previous words
examples
0-gram LM (uniform model) … p(w)=1/∣V∣
1-gram LM … we store p(w) for every word
2-gram LM … p(wi∣wi−1) for every pair of words
3-gram LM … p(wi∣wi−2,wi−1) etc.
so in 3-gram LM, we estimate p(W)=p(w1∣s,s)⋅p(w2∣s,w1)⋅p(w3∣w1,w2)⋅p(w4∣w2,w3)⋅…⋅p(wn∣wn−2,wn−1)
Describe how Maximum Likelihood estimate of a trigram language model is computed. (2 points)
we estimate p(wi∣wi−2,wi−1)=c2(wi−2,wi−1)c3(wi−2,wi−1,wi)
to get c3, we count sequences of three words in training data
to get c2 we count sequences of two words
we can either get it from c3
c2(y,z)=∑wc3(y,z,w)
or count differently at the beginning of the data
Why do we need smoothing (in language modelling)?
in the trigram model, there will be always some zeros
however, we cannot be sure that the trigram really does not exist in the language as our data is possibly incomplete
when calculating the probability of a sequence, one trigram with zero probability makes the whole sequence have zero probability, which is impractical
we need to make the system more robust and avoid infinite cross entropy (this happens when test data contain an event which has not been seen in training data)
solution: redistribute probabilities (take from non-zero words, give to words with zero probabilities)
Give at least two examples of smoothing methods. (2 points)
add 1
∀w∈V:p′(w∣h)=c(h)+∣V∣c(h,w)+1
h … history
V … vocabulary
problem if ∣V∣>c(h), it happens often
add less than 1
p′(w∣h)=c(h)+λ∣V∣c(h,w)+λ
λ<1
we choose λ in a way that minimizes cross-entropy of p′ relative to holdout (dev) data
cross-entropy of q relative to p: H(p,q)=−Ep[logq]
linear interpolation, multiple lambdas
p′(wi∣wi−2,wi−1)=λ3p3(wi∣wi−2,wi−1)
+λ2p2(wi∣wi−1)+λ1p1(wi)+λ0/∣V∣
we can normalize it so that…
λi>0
∑iλi=1
λ0=1−λ1−λ2−λ3
estimated using expectation maximization (EM) algorithm
another version: bucketed smoothing
Morphological analysis
What is a morphological tag? List at least five features that are often encoded in morphological tag sets.
morphological tag = a summary of the grammatical information about a specific word in the given context
features: part of speech, case (pád) number, gender, person, mood (způsob), tense, animacy (životnost), degree, voice (rod), aspect (vid), polarity (zápor), …
List the open and closed part-of-speech classes and explain the difference between open and closed classes.
words can be enumerated (even though these classes also evolve but over longer period of time)
the words are typically not base for derivation
Explain the difference between a finite-state automaton and a finite-state transducer. Describe the algorithm of using a finite-state transducer to transform a surface string to a lexical string (pseudocode or source code in your favorite programming language). (2 points)
finite-state machine is a five-tuple (A,Q,P,q0,F)
input alphabet A, set of states Q, transition function P, initial state q0, accepting states F
it can accept or reject a word
morphology of a language can be described using a finite-state automaton
attaching a suffix may result in phoneme or grapheme (spelling) changes
we call this phonology for simplicity
plural of baby is not *babys but babies
we will use two-level morphology: upper (lexical) language and lower (surface) language
finite-state transducer
a type of finite-state automaton that maps between two sets of symbols
pairs (r:s) from finite alphabets R and S
R … lexical language
S … surface language
tasks: analysis (get lexical string based on a surface string), generation (generate surface string from a lexical string)
difference
FSA defines a set of accepted strings (lexicon)
FST defines a relation between sets of strings (lexical string → surface string or surface → lexical)
algorithm
initialize set of paths P={}
read input symbols one-by-one
for each input symbol x:
generate all lexical symbols y that may correspond to the empty symbol y:0
repeat until the maximum possible number of subsequent zeros is reached:
extend all paths in P by all corresponding pairs y:0
check all new extensions against the phonological transducers and the lexical automaton; remove disallowed paths (partial solutions) from P
generate all possible lexical symbols z for the current input symbol x (pairs z:x); extend each path in P by all such pairs
check all paths in P (the next transition in FST/FSA); remove impossible paths
collect glosses from the lexicon for all paths that survived
Give an example of a phonological or an orthographical change caused by morphological inflection (any natural language). Describe the rule that would take care of the change during analysis or generation. It is not required that you draw a transducer, although drawing a transducer is one of the possible ways of describing the rule.
Czech: káď → kádě
ď:d <= _ +:0 e:ě
káď+e (lexical)
kád0ě (surface)
complete version of the rule: [ď:d | ň:n | ť:t] <=> _ +:0 [e:ě | i:i | í:í]
another example: nať → nati
Give an example of a long-distance dependency in morphology (any natural language). How would you handle it in a morphological analyzer?
umlauts in German plurals
Buch → Bücher
simplified rule: u:ü <= _ c:c h:h +:0 e:e r:r
Buch+er (lexical)
Büch0er (surface)
context should contain +:0 and perhaps test end of word (#)
this is too simplified, the suffix must be plural and the stem must be marked for plural umlauting (Kocher and Besucher are correct!)
capturing long-distance dependencies is clumsy
Kraut / Kräuter has different intervening symbols → different rule
a transducer could be more general but it would probably overgenerate
Syntactic analysis
Describe dependency trees, constituent trees, differences between them and phenomena that must be addressed when converting between them. (2 points)
constituent tree
sentence is divided to phrases (contituents)
recursive: phrases are divided into smaller phrases
the smallest phrases are words
dependency tree
similar to “větný rozbor” taught in Czech schools (there are some differences, e.g., in dependency trees, the subject depends on the verb)
graph of dependencies between words (constituents)
head of phrase = governing node, parent node
the other nodes are dependent nodes
differences
phrase (constituent) trees
usually do not mark the head
may not mark the function of the constituent in the superordinate constituent
do not show nonterminals (phrase types, like NP, VP, …) nor any other phrase-level features
do not show “how the sentence is generated” (order, recursion, proximity of constituents)
Give an example of a sentence (in any natural language) that has at least two plausible, semantically different syntactic analyses (readings). Draw the corresponding dependency trees and explain the difference in meaning. Are there other additional readings that are less probable but still grammatically acceptable? (2 points)
I saw the man with a telescope.
saw with a telescope × man with a telescope
Ženu holí stroj.
(já) ženu (čím?) holí (koho, co?) stroj
ženu – root/verb
holí – adverbial
stroj – object
(koho?) ženu (čím?) holí (ty) stroj
stroj – root/verb
ženu – subject
holí – adverbial
(koho?) ženu holí (kdo, co?) stroj
holí – root/verb
stroj – subject
ženu – object
there will be always a special node for the period (punctuation)
What is coordination? Why is it difficult in dependency parsing? How would you capture coordination in a dependency structure? What are the advantages and disadvantages of your solution?
examples
chickens, hens, rabbits, cats, and dogs
new or even newer
quickly and finely
either now or later
the sun was shining, so we went outside
there is no real head → difficult to capture in dependency trees
the coordinate phrases (conjuncts) are usually of the same type
my solution
add a special node acting as a root of the coordination
advantage: we do not emphasize any of the conjuncts as the most important
disadvantage: we add a new element that was not in the original sentence
What is ellipsis? Why is it difficult in parsing? Give examples of different kinds of ellipsis (any natural language).
a phrase omitted from the sentence (its surface form) although it is present in the underlying meaning (deep structure)
to parse the sentence correctly, we need to deduce some missing information from the context
examples
Whom did you see there? — Peter. (missing verb)
Czech and German researchers discussed… (it means that Czech researchers and German researchers discussed; another possible meaning is that every researcher was both Czech and German)
The Penguins are leading 4:0, while the Colorado Avalanches only 3:2. (missing verb in the second part)
Sedím. (omitted subject; the information is contained in the verb form)
Information retrieval
Explain the difference between information need and query.
information need
a topic that the user desires to know more about
a vague idea of what the user is looking for
query
what the user conveys to the computer in an attempt to communicate the information need
formal statement of information need
What is inverted index and what are the optimal data structures for it?
for each term in the dictionary, we store a list of all documents that contain it (postings; ids of such documents)
the lists of documents should be sorted so that we can easily merge/intersect them
an optimal data structure for storing an inverted index is a hash table or a tree (binary search tree, B-tree, …)
What is stopword and what is it useful for?
stop words = extremely common words which would appear to be of little value in helping select documents matching a user need
examples: a, an, and, are, as, at, be, by, for, from, …
it may be useful to skip the words to save the space needed to store the postings
however, you need stop words for phrase queries like “King of Denmark”
Explain the bag-of-word principle?
we do not consider the order of words in a document
we only store the information whether the document contains a given word (and how many such words it contains)
What is the main advantage and disadvantage of boolean model.
advantage
the model is simple and fast; we do not need any scoring function
good for experts: precise understanding of the needs and collection
good for applications: can easily consume thousands of results
disadvantage
not good for the majority of users
most users are not capable or lazy to write Boolean queries
Boolean queries often result in either too few or too many results
in Boolean retrieval, it takes a lot of skill to come up with a query that produces a manageable number of hits
solution: ranked retrieval
we score the documents by relevance
show the top 10 results
Explain the role of the two components in the TF-IDF weighting scheme.
tf-idf … measure of importance of a word to a document in a collection
tf-idf weight of a term is product of its tf weight and its idf weight
wt,d=(1+logtft,d)⋅logdftN
tft,d … term frequency (number of times that t occurs in d)
dft … document frequency (number of documents in the collection that t occurs in)
the fewer documents t appears in, the more informative it is
the collection has N documents in total
idf … inverse document frequency
Explain length normalization in vector space model what is it useful for?
we represent the documents and the query as vectors in a vector space
it is a bad idea to use Euclidean distance as a measure of similarity
Euclidean distance is large for vectors of different lengths
instead, we use cosine similarity cos(q,d)=∣q∣⋅∣d∣q⋅d where q,d are vectors
this normalizes the vector lengths
Language data resources
Explain what a corpus is.
dataset of language resources, collection of texts
it is often annotated
it should be somehow balanced
there are special types of corpora: spoken, parallel, domain-specific, diachronic
Explain what annotation is (in the context of language resources). What types of annotation do you know? (2 points)
annotation = adding selected linguistic information in an explicit form to a corpus
raw texts are difficult to exploit
examples
morphological annotation – lemma, POS, other categories)
syntactic annotation – constituent trees, dependency trees
semantic annotation – dozens of approaches, no consensus so far
anaphora – “what does the pronoun refer to?”
word sense disambiguated corpora – which sense is used for a given polysemous word in a given context
sentiment corpora – positive/negative emotions induced by some expressions in a text
What are the reasons for variability of even basic types of annotation, such as the annotation of morphological categories (parts of speech etc.).
different languages may have different morphological categories
different linguistic traditions of different national schools
Explain what a treebank is. Why trees are used? (2 points)
treebank = a corpus in which the syntax and/or semantics of sentences is analyzed using tree-shaped data structures
why trees? we believe that…
trees are attractive data structures :D
sentences can be represented by discrete units and relations among them
some relations make more sense than others
there is an identifiable discrete structure hidden in each sentence
the structure must allow for various kinds of nestedness → recursivity → trees
two types of trees that are broadly used: constituency (phrase-structure) trees, dependency trees
Explain what a parallel corpus is. What kind of alignments can we distinguish? (2 points)
it contains texts in two (or more) languages
the texts are aligned (for example, we know which Czech and English documents are equivalent)
there are multiple possible levels of alignment
document level alignment
sentence level alignment
word level alignment
(morpheme level alignment?)
examples
The Rosetta Stone
CzEng
Canadian parliamentary transcripts (Hansard)
What is a sentiment-annotated corpus? How can it be used?
it captures the attitude (emotional polarity) of a speaker with respect to some topic/expression
examples
“it was an ok (neutral) club, but terribly crowded (negative)”
“Taiwan-made products stood a good chance (positive) of becoming even more competitive thanks to (positive) wider access to overseas markets”
obviously over-simplified, but highly demanded e.g. by the marketing industry
What is a coreference-annotated corpus?
it captures relations between expressions that refer to the same entity of the real world
for example, the expressions “Audi”, “the company”, and “the Audi company” all refer to one entity
example of a coreference-annotated corpus: Prague Dependency Treebanks
Explain how WordNet is structured?
it is a hyponymy forest composed of synsets (sets of synonymous words)
example of a branch
event
act, human action, human activity
action
change
motion, movement, move
locomotion, travel
run, running
dash, sprint
another subbranch
motion, movement, move
descent
jump, parachuting
Explain the difference between derivation and inflection?
inflection = ohýbání (skloňování, časování)
change in the form of a word to express a grammatical function/attribute (tense, mood, person, number, case, gender)
derivation = odvození
forming a new word from an existing word
usually prefixing and suffixing
inflection does not change the core meaning of the word
derivation produces a new word (a distinct lexeme), inflection produces grammatical variants of the same word
Evaluation measures in NLP
Give at least two examples of situations in which measuring a percentage accuracy is not adequate.
if the classes are imbalanced (e.g. a rare disease)
if there is more than one correct answer for each instance
if our system does not give exactly one answer for each instance
if there are some errors that are more wrong than others
Explain: precision, recall
let's assume our system either gives prediction (”positive”) or does nothing (“negative”)
precision = if our systems gives a prediction, what’s its avarage quality
correct answers given ÷ all answers given
tp+fptp
recall = what average proportion of all possible correct answers is given by our system
correct answers given ÷ all possible correct answers
tp+fntp
What is F-measure, what is it useful for?
weighted harmonic mean of precision and recall
Fβ=β2P+R(β2+1)PR
F1=P+R2PR
why?
using both precision and recall means that we are in 2D
“is it better to have a system with P=0.8 and R=0.2, or P=0.9 and R=0.1?”
we want to be able to use a single scale → F-measure
What is k-fold cross-validation?
it is a special way to train and evaluate a (ML) model based on train/test data
used especially in the case of very small data, when an actual train/test division could have huge impact on the measured quantities
we partition the data into k subsamples
we train the model based on k−1 subsamples and evaluate it using the last unused subsample → we get a score
we repeat this k times so that every time, we use a different subsample for evaluation → we get k scores and compute their average (this is our final score)
Explain BLEU (the exact formula not needed, just the main principles).
BLEU = bilingual evaluation understudy
it is a common measure in machine translation
it measures similarity between a machine's output and a human translation
usually, there are multiple reference (human) translations
n-gram precision = C/N
where N … number of n-grams that the candidate translation contains
and C … number of n-grams from the candidate translation that exist in at least one reference translation
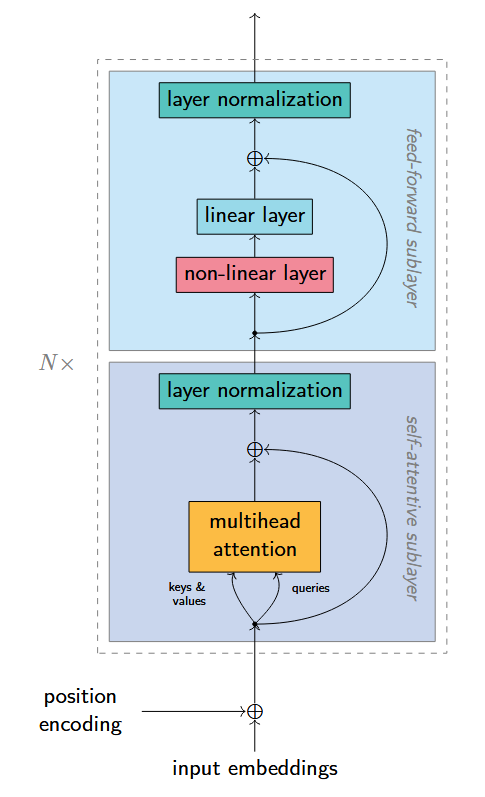
each layer has two sublayers (self-attention and feed-forward)
Why do we use positional encodings in the Transformer model.
attention mechanism does not have any information about the order of the tokens
one way to solve this is to sum positional coefficients with the token embeddings
What are residual connections in neural networks? Why do we use them?
we always sum the output of the sublayer with the output of the previous sublayer
we use them to make the learning numerically stable and to prevent the vanishing gradient problem
in a deep network, there are many forward propagation steps and the gradients of earlier weights (layers) are calculated with too many multiplications → they become too small
to solve this, we add the output of the previous sublayer to the output of the current one
it helps, because summation is linear with respect to the gradient
Use formulas to express the loss function for training sequence labeling tasks.
we use cross-entropy between estimated distribution P and one-hot ground-truth distribution T
for a single item
L=H(T,P)=−Ei∼TlogP(i)=−∑iT(i)logP(i)=−logP(y∗)
y∗ … ground truth
for a sequence of T items
L=−∑t=1TlogPt(yt∗)
Explain the pre-training procedure of the BERT model. (2 points)
it is a “masked language model”
it is trained as sequence labeling: change some input token, labeler guesses original tokens
when trained, throw away labeling, use last layer as the representation
for some of the words in the training data (randomly sampled; 15 % in the original paper), we do one of the following things:
with 80% probability replace the word with special MASK token
with 10% probability replace the word with a random token
with 10% probability keep the original word
the classifier should then predict the correct (original) word
Explain what is the pre-train and finetune paradigm in NLP.
two steps: pre-training and finetuning
pre-training
do once, large (unlabeled) data, long time
for example, masked language modeling
finetuning
small data (task-specific), fast
to fulfill a task-specific objective
Describe the task of named entitity recognition (NER). Explain the intution behind the CRF models compared to standard sequence labeling. (2 points)
the goal of named entity recognition is to find named entities in the text
examples of named entities: person, location, organization, event, product, skill, address, phone, email, URL, IP, datetime, quantity
it is linked to coreference resolution
usage: entity linking, indexing text for search, direct use in smart devices (making addresses clickable etc.)
the entities can span multiple words; they can be nested
there are multiple schemes to deal with that
example (IOB scheme)
There are over 1000 compositions by Johan Sebastian Bach.
O O B-QUANT I-QUANT O O B-PERSON I-PERSON I-PERSON O
standard tagging
conditional independence assumption
but tags have their internal grammar: I-PERSON cannot follow after O
CRF (Conditional Random Fields)
instead of doing probability distribution over each token independently, we do a probability distribution over all possible tagging sequences
for a tagging sequence, we get a score, how probable it is
Explain how does the self-attention differ in encoder-only and decoder-only models.
encoder-only models
predict sentence labeling (e.g. POS tags)
the self-attention mechanism can look in all directions (at the previous and following tokens)
decoder-only models
predict the next word
we have to ensure that the self-attention mechanism cannot look at the future words
we need to use a mask (a triangular matrix with negative infinities)
Machine translation fundamentals
Why is MT difficult from linguistic point of view? Provide examples and explanation for at least three different phenomena. (2 points)
ambiguity and word senses
“The plant is next to the bank.”
”Ženu holí stroj.”
a single word can have several meanings
target word forms
tenses, cases, genders
it is necessary to select the right word form
“The cat is on the mat.” → kočka
“He saw a cat.” → kočku
negation
French negation is around the verb: “Je ne parle pas français.”
Czech negation is doubled: “Nemám žádné námitky.”
phrases with negation can be ambiguous
pronouns
English requires the subject explicit; in Czech, the information is implicitly in the verb
Četl knihu. He read a book.
Spal jsem. I slept.
the gender must match the referent
He saw a book; it was red.
Viděl knihu. Byla černá.
tricky “svůj”
Could I use your cell phone?
an old machine translation: Mohl bych používat svůj mobilní telefon?
coordination and apposition, word order
“This book is dedicated to my parents, Ayn Rand and God.”
space of possible translations
there are many correct translations
idioms
cultural context (local time, customs, etc.)
Why is MT difficult from computational point of view?
the space of possible translations is quite large – there are many bad translations but also many acceptable translations
there is a lot of ambiguity in language; language is messy (not all sentences are grammatical)
evaluation is hard
Briefly describe at least three methods of manual MT evaluation. (1-2 points)
ranking of constituents on the scale 1–5
we see the original sentence, reference translation, and several machine translations
we assign a score to the highlighted part (constituent) of the translated sentence
this way, we do not evaluate overall coherence, which can be important
ranking sentences
scoring the whole sentences
eye tracking can be used
long sentences are hard to rank
candidates are incomparably poor :(
comprehension test
blind editing + correctness check
first, we look at the result (without seeing the original sentence) and edit it to make it as fluent as possible
second, the edited sentences are checked against the originals (whether the meaning is the same)
task-based
does MT output help as much as the original?
do I dress appropriately given a translated weather forecast?
evaluation by flagging errors
classification of MT errors
we label the words/phrases in the MT output using the corresponding errors
Describe BLEU. 1 point for the core properties explained, 1 point for the (commented) formula.
it is based on geometric mean of n-gram precision and a brevity penalty
each feature function hm(e,f) relates source f to target e
model weights λm specify the relative importance of features
the constant denominator is not needed in maximization
e^=argmaxeexp(∑mλmhm(e,f))
log-linear model → Noisy channel
we consider equal widths and only two features
hTM(e,f)=logp(f∣e)
hLM(e,f)=logp(e)
e^=argmaxeexp(∑mλmhm(e,f))
=argmaxeexp(hTM(e,f)+hLM(e,f))
=argmaxeexp(logp(f∣e)+logp(e))
=argmaxep(f∣e)⋅p(e)
Describe the loop of weight optimization for the log-linear model as used in phrase-based MT.
MERT (Minimum Error Rate Training) loop
(start with some initial weights λ1,…,λM)
translate input
evaluate candidates using an external score
find new weights for a better match of external and internal score
if the internal weights stayed the same, stop; otherwise loop
Neural machine translation
Describe the critical limitation of PBMT that NMT solves. Provide example training data and example input where PBMT is very likely to introduce an error.
PBMT = phrase-based machine translation
limitation: too strong phrase-independence assumption
but phrases do depend on each other
example training data
Nemám žádného psa. → I have no dog.
Viděl kočku. → He saw a cat.
example input
Nemám kočku. (→ I have a cat.)
the negation is expressed not only as “žádného” but also in the verb
Use formulas to highlight the similarity of NMT and LMs.
if we modeled p(e∣f) directly…
p(e∣f)=p(e1,…,eI∣f)=∏i=1Ip(ei∣e1,…,ei−1,f)
this is “just a cleverer language model”
p(e)=∏i=1Ip(ei∣e1,…,ei−1)
a neural network with a single hidden layer (possibly huge) can approximate any continuous function to any precision
we will use NNs to model p(ei∣e1,…,ei−1,f)
“what is the next word in the translated sentence?”
Describe, how words are fed to current NMT architectures and explain why is this beneficial over 1-hot representation.
using word embeddings
each word is mapped to a dense vector
in practice 300–2000 dimensions are used (they have no clear interpretation)
embeddings are trained for each particular task
in 1-hot representation, there are no relations among the words; they are all equally close/far
word embeddings somehow reflect the meanings of the words
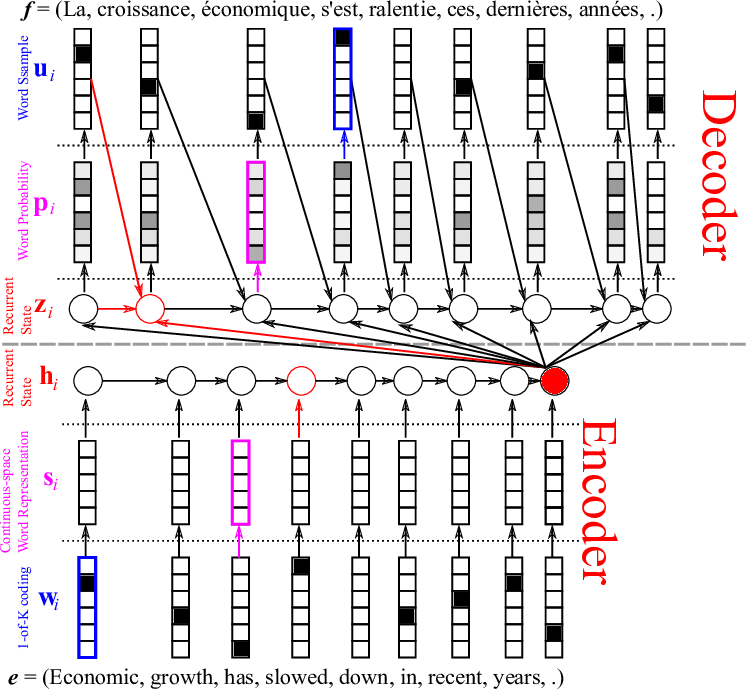
Sketch the structure of an encoder-decoder architecture of neural MT, remember to describe the components in the picture (2 points)
the encoder first processed the English sentence, then the decoder generated the French sentence
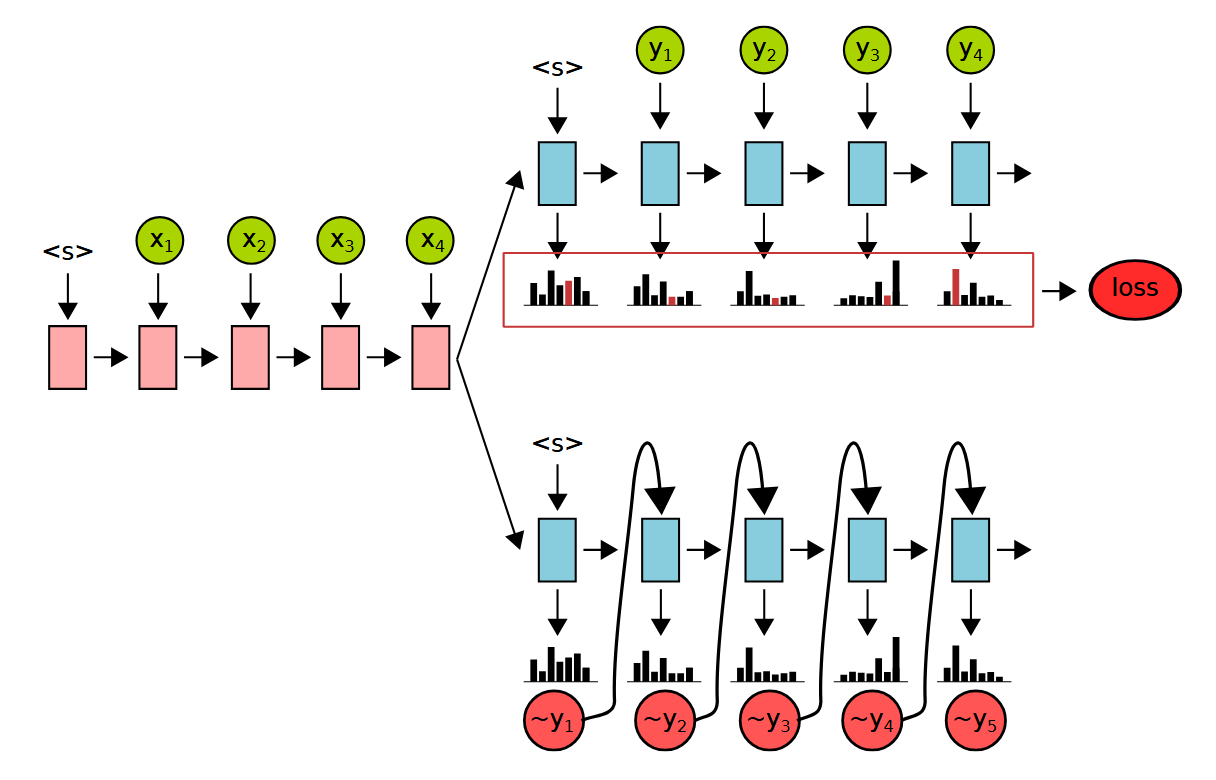
What is the difference in RNN decoder application at training time vs. at runtime?
at runtime, the decoder generates the next word based on the previous generated word and its internal (hidden) state
at training time, we “force” the decoder to produce the target sentence (kind of)
the decoder generates the probability distribution of the next word based on the previous target word and its internal state
we get the loss function from the probability distributions (their difference from the one-hot distributions of target words)
the two applications of the decoder are on the right: the training phase is on top; the runtime is below
What problem does attention in NMT address? Provide the key idea of the method.
arbitrary-length sentences fit badly into a fixed vector
without attention
encoder needs to compress the information contained in the original (source) sentence
for longer sentences, important details can be lost
attention allows the decoder to look at different parts of the source sentence at each decoding step
it uses a weighted sum
What problem/task do both RNN and self-attention resolve and what is the main benefit of self-attention over RNN?
the problem of representing source sentence (of an arbitrary length) using a fixed-size vector
RNN
it has turned out that reading input backwards (in RNNs) works better: the information contained in the early words is not diluted that much when generating the first words of the translation
bi-directional RNN can be used to “attend” to all hidden states
we could use the two outputs of the encoder – reading the sentence forwards and backwards
but the middle words would be still quite lost in the representation
self-attention
the decoder can look at any hidden state of the encoder (kind of)
there is a sub-network predicting the importance of source states at each step
What are the three roles each state at a Transformer encoder layer takes in self-attention.
query, key, value
to get any of the roles based on the word (embedding), we multiply the word by a corresponding weight matrix (WQ, WK, or WV)
by multiplying queries and keys (and softmaxing them), the self-attention mechanism finds which words are relevant – then gets their values
What are the three uses of self-attention in the Transformer model?
encoder-decoder attention
Q … previous decoder layers
K=V … outputs of encoder
decoder positions attend to all positions of the input
encoder self-attention
Q=K=V … outputs of the previous layer of the encoder
encoder positions attend to all positions of previous layer
decoder self-attention
Q=K=V … outputs of the previous decoder layer
masking used to prevent depending on future outputs
decoder attends to all its previous outputs
Provide an example of NMT improvement that was assumed to come from additional linguistic information but occurred also for a simpler reason.
interleaving the generated output with syntax tags
it was better than generating output without tags
but with random tags, the model achieved even better results (when using seq2seq)
likely reason: the model had “more thinking time” (the decoder was “deeper”)
requiring that one of the self-attention heads in one of the layers corresponds to dependency tree of the source sentence
it improved the performance of the model
but again, producing a “linear” (dummy) tree improved the performance even more
Summarize and compare the strategy of "classical statistical MT" vs. the strategy of neural approaches to MT.
goal of “classical” SMT
find minimum translation units / graph partitions
such that they are frequent across many sentence pairs
without imposing (too hard) constraints on reordering
in an unsupervised fashion
there is the independence assumption of the translation units