processing: reasoning focused on the image, pixels, pixel groups
vision: focuses on the knowledge the image brings from a real scene
difficult problem
the goal of computer vision is not to mimic human vision but to build systems that extract information
computer vision is an inverse of the synthesis problem
projection is fundamentally ambiguous – we are losing information (depth, size, occlusions)
in general it's an ill-posed problem: no unique solution for a given observation, ambiguous solutions, incomplete data (example: scale of the observed scene, toy car instead of normal car)
need of injecting a priori knowledge and regularization (example: penalize non-smooth solutions)
from noisy observations, we estimate the parameters of a model
a priori knowledge: physics, geometry, semantics
example: by counting visible wheels of the car, we can tell the position of the camera
desirable characteristics
robustness – be able to identify observation noise/errors (have plan B in case of error)
speed
precision
generality – the algorithm should be generic; the pool of situations that it can handle should be large enough
main vision problems
calibration – where is the camera, which model, …
segmentation – which parts of the image belong together
detection – what is interesting/salient in the image
reconstruction – where are the objects (position, shape, 3D surface)
tracking – which motion is present in the image, how do objects move
recognition – what do we see, semantics
image – 2D signal (depicts a 3D scene), matrix of values that represent a signal, has semantic information
light
plays a fundamental role in 3D perception
no light → no image
shadow, diffuse reflection (in many directions), specular reflection (mirror-like, in one direction)
wavelength, spectrums
solar spectrum: almost continuous spectrum, some wavelengths are stronger
white light: continuous spectrum (energy evenly distributed)
sodium vapor lamp: only yellow → red car appears dark
what happens when a light ray hits the surface
absorption (black surface)
reflection, refraction (mirror, reflector)
diffusion (milk)
fluorescence
transmission and emission (human skin)
most surfaces can be approximated by simple models
first simplified hypothesis
no fluorescent surfaces
“cold” objects (they don't emit light)
all light emitted from a surface point is formed solely by the light arriving there
standard model: BRDF
bi-directional reflectance distribution function
models the ratio of energy for each wavelength λ
incoming from direction v^i
emitted towards direction v^r
reciprocity (we can swap the light source and the camera)
isotropy (no favorite direction) – does not always hold
energy corresponds to an integral (we can use a discrete sum)
Lambertian assumption
diffuse surface: uniform in all directions (paper, milk, matt paint)
the BRDF is a constant function fd(v^i,v^r,n^,λ)=fd(λ)
“when a ray hits the surface, it spreads equally in all directions”
do papers use it?
plenoptic function – does not assume, explicitly models angular dimension (intensity may be different)
focused plenoptic camera – using it for matching and processing depth
depth estimation – yes (for the rays)
spray on optics – yes (required by matching of the droplets)
Middlebury – putting the clay on
SPIN
ViT, DINO
specular (reflective) material, central lobe on s^i
use local (not global) characteristics – more robust to occlusions
invariance to translation, rotation, scale, lightning
robust to noise, bad conditions, compression
discriminative – allow to identify objects
quantity – we need enough points
precision – accurate location of the object in the image
efficiency – fast computation
Moravec's detector
small window (does shifting it lead to a change of intensity?)
if a shift of the window in any direction results in an intensity change, we have found a corner
Harris detector – “differentiable Moravec”
Taylor expansion
bilinear form
eigenvalues
minimum eigenvalue – slowest change direction
maximum eigenvalue – fastest change direction
hard to compute → we use R instead
R=detM−α(traceM)2
R>0⟹ corner
R<0⟹ contour
small ∣R∣⟹ homogeneous region
algorithm
compute derivatives of the image (using Sobel…)
compute R in each point
find points with a high R (over certain threshold)
keep the local maxima of R
we don't want too many interest points, various strategies (keep top k points per image; ensure that every n pixels radius has its top interest point)
properties
rotation invariance
invariance to intensity shift, partial invariance to intensity scaling
no invariance to scale changes
we consider circular regions of different sizes on a point
but how to choose them?
scale invariant detector
image pyramid (consider several smaller versions of the same image)
scale invariant function which serves as a basis for the detection algorithm – LoG, we can also use difference of Gaussians (DoG) which is similar (but more efficient to compute)
Harris-Laplacian detector – find the local max. of…
Harris detector in image space (coordinates)
LoG in the scale space
SIFT (Lowe) – find the local max. of DoG in image space and scale space
how to match detected points?
we need descriptors – should be invariant and discriminant
Harris: use eigen values? not so discriminant
windowed approaches – not so invariant
multi-scale oriented patches (MOPS) – oriented patch of size 8×8 (orientation from the image gradient)
scale invariant feature transform (SIFT) – histogram of local gradient directions (the maximum defines the principal direction)
matching approaches
two-way matching (are we the best match for our best match?)
exhaustive search is slow
hashing is faster (compute a hash value for the descriptor)
nearest neighbour
k-dimensional tree, best bin first (BBF)
Paper Session 1
plenoptic function, early vision
systematic framework capturing visual information
plenoptic function
P(x,y,t,λ,Vx,Vy,Vz)
output – intensity
t time, λ wavelength, V viewing point
humans – only two samples along Vx axis (both for a single value of Vy and Vz)
extraction of information … derivatives
“periodic table”
“blobs” – convolutional filters for extracting information
focused plenoptic camera
angular–spatial resolution tradeoff
hi-res rendering algorithm
depth estimation
we want
simultaneous detection and depth estimation
local method to detect rays
method invariant to object size and depth
ray gaussian kernel
lisad – operator activation
ray = light
we stack pictures taken from different angles
on the cut, there are “rays” → we can get depth (thanks to parallax)
if we move, the objects in the foreground shift
the objects in the background not that much
spray-on optics
drop extraction and simulation + remove distortion
match the images
what is the final resolution?
manual droplet segmentation
better image quality with more droplets
how to get real data? ground truth?
usually, we need both synthetic and real data
3D Vision
definitions & notation
point p∈R3
matrix M∈Rm×n (m rows, n columns)
line … ax+by+c=0
(a,b,c)(x,y,1)T=0 … dot product
one interpretation of dot product – projection of one vector into the other
cross product of vectors ∈R3
computed using determinants of 2×2 matrices (with alternating signs)
x×y=(x2y3−x3y2,x3y1−x1y3,x1y2−x2y1)
determinant
det(AB)=detA⋅detB
determinant zero/nonzero, co-linearity of column vectors
equivalence
X∼Y if ∃λ=0:λX=Y
homogeneous coordinates – we add a one at the end of the vector, so instead of (x,y) we get (x,y,1)
Cholesky decomposition
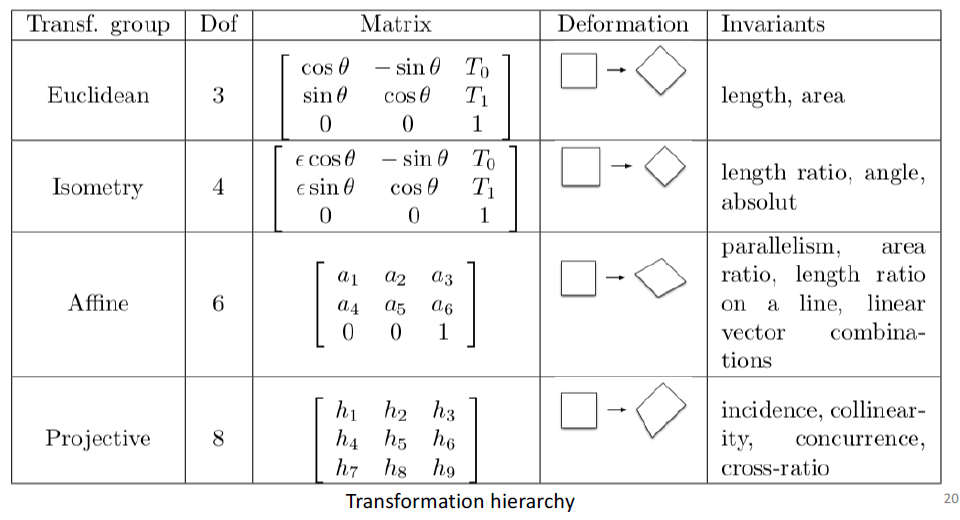
projective geometry
perspective deformation can be modeled with 2D projective transformation
for a homography H transforming points, the associated transformation for lines is H−T
ℓTx=0
ℓTH−1Hx=0
(H−Tℓ)THx=0
affine transformation preserve parallelism
parallel lines … L1×L2=(x,y,0)T
L1′×L2′=H(x,y,0)T
if H is affine transformation, it preserves the last 0 (projective transformation might not preserve it)
3D geometry
elementary transformations
translation T=100001000010TxTyTz1
rotations R=Rz⋅Ry⋅Rx
detR=1
R−1=RT
Rx=10000cosθsinθ00−sinθcosθ00001
Ry=cosθ0−sinθ00100sinθ0cosθ00001
Rz=cosθsinθ00−sinθcosθ0000100001
perspective projections
into the optical centre
focal length f … distance between the projection centre and the image plane
image point (x,y,z=f), world point (X,Y,Z), optical axis z
here, we consider that the origin of the axes and the projection centre are the same point
perspective projection matrix 100001000011/f0000 to get an image point from a world point
can be deduced using intercept theorem (triangle similarity)
so x=fX/Z (and y=fY/Z)
parallel lines intersect at infinity – this location defines a vanishing point in the image
for lines in a plane, vanishing points define a horizon line
parallel projections (ortographic)
projection is perpendicular to the image plane
we simply remove one coordinate (set to zero)
as if f→+∞
exercise
you have a projection matrix P
you move the camera or rotate it (you apply T), how does the new projection matrix look like?
P′=TPT−1
first, we return to the original projection space using T−1 (we move the point there)
we apply the projection P
then, we come back using T
sanity check: consider a zero transformation (e.g. for a parameterized rotation matrix, set α=0) → it should hold that P∼P′
note: the (projected) size of the object is proportional to its distance from the optical plane
so if we turn the camera (while keeping the focal length), the object gets smaller or larger
vertigo effect: you move the camera (toward or away from an object) and update the focal length to make the object appear the same size (but the background changes)
camera models
most used camera model – pinhole model (perspective projection)
full transformation composed of
rigid transformation: world coordinates → camera coordinates
both 3D, only rotation & translation
perspective projection into the retinal plane (2D)
limitation: we cannot do non-linear reparametrization (like switching from Cartesian to polar coordinates)
encoder → code (“bottleneck”) → decoder
code size is very important
too big → overfit, lack of interest
too small → loss of information
denoising AE
add noise to input image
pass through network
measure reconstruction loss against original image
for PCA, we can interpolate (we can safely take a point between too points and it's meaningful)
generally, AEs can lead to an irregular latent space (with no meaningful interpolation → close points in the latent space are not similar when decoded)
we want to regularize the latent space to enable generation → variational AE
so an input is encoded as a distribution (not as a point) in the latent space
regularization using KL-divergence
closed form for two normal distributions
the decoder then decodes a sample from the distribution
the loss consists of the distance of the decoded image from the original and the KL divergence of the encoded distribution from the N(0,I) distribution
how to sample to allow backpropagation?
reparametrization trick
instead of sampling z from N(μx,σx), we always sample ζ from N(0,I) and then compute z=σxζ+μx
so we can differentiate z (and backpropagate)
limitation: images are blurry
generative adversarial network
generator, training set, discriminator
trying to match the real distribution
goal: fool the discriminator
GANs get sharper images than VAEs
VAEs use mean square error, producing sharp edges is not worth the risk
GAN discriminator can easily spot blurry images
diffusion models
slowly destroy structure in data distribution by adding noise
parameter βt (for time t) that governs the noise distribution (Gaussian)
its schedule affects the learning
the model tries to remove the noise
only step by step to improve stability
trained using U-Net (with adjustments)
can be conditioned with other inputs (other images, text, style, …)
then ϵ gets another parameter
Stable Diffusion uses CLIP to transform text into embeddings for conditioning
ways to make diffusion faster – distillation, one step diffusion
diffusion vs. GANs
training stability
GAN's optimum is a saddle point (min max)
diffusion is more stable
diversity
GANs have a risk of mode collapse (generating just one type of output)
we are updating the state with multiplication and addition
forget gate: is this worth remembering (multiplying by a number ∈[0,1])
input gate: what new information are we storing in the cell state
output gate: output of the cell
variants: peephole connections (let gate layers look at the cell state), grouping forget and keep gates, GRU (gated recurrent unit)
types: one to one, one to many, many to one, many to many (2×)
problems
GRU still forgets stuff (especially with long sequences)
processing is sequential, hard to parallelize on GPUs
→ Transformer architecture
existing tasks are solved (to some extent)
new tasks need to be created → ARC-AGI datasets
Paper Session 2
ViT
self-attention can be as expressive as convolutional layer
image split into patches
encoder-only Transformer, learned position embeddings (capture relative distances of patches)
needs enough data to learn patterns (in CNNs, there is inductive bias)
DINO
emerging properties in self-supervised vision transformers
ViT limitations
supervised labels are coarse (one image – one label)
no explicit pressure to learn object boundaries, parts vs. background, spatial grouping
idea: use self-supervised pre-training
knowledge distillation with no labels
different crops
teacher gets only global
student gets all crops
→ enforce local-to-global correspondences
to avoid mode collapse – centering and sharpening applied to the teacher's output
we are forcing the teacher to “be creative” when predicting distribution
sharpening prevents the distribution from being flat
centering prevents the distribution to always peak at the same place (by computing a running average)
setup
MLP on top of [class] encoding (like in ViT) → distribution
goal: minimize cross-entropy between student and teacher
hi-res stereo datasets with subpixel ground truth (Middlebury)
capturing objects with stereo camera
how to create such datasets
two rounds of calibration (using checkerboard)
code images to get depth
ambient images
imperfection – useful for evaluation (real-world images are not perfect)
nothing in the world is perfect
pose reconstruction
SMPL body model – shape & pose
two approaches
regression – predicts shape & pose based on the image
optimization – optimizes shape & pose based on camera parameters and ground truth of 2D joints (and initial shape & pose)
SPIN combines both
initializes optimization with regression outputs
uses optimization to supervise regression
Practical Units
Augmented Reality
detection – detecting, refining, and drawing the projected image points of the checkerboard from a captured image
implement simple checkerboard spot detection with findChessboardCorners on grayscale version of the input image
draw the checkerboard points on the color input image with drawChessboardCorners.
the points from question 1 can be improved in precision by refining based on a local window around the initial detections (before drawing the checkerboard points, add the refinement step using cornerSubPix)
calibration, positioning
calibrate the camera using calibrateCamera (3D to 2D matches at every detection that will be given to this function)
find the camera extrinsics using solvePnPRansac
use projectPoints to find the 2D reprojections of the 3D points using the estimated intrinsics and extrinsics to check that the result is correct
drawing using reprojected points
the coordinates of a 3D cube are provided which you can use as initial augmentation object, but you can draw whatever you wish (use circle, line, drawContours for this purpose)
3D Shape Modeling
at the beginning of the file the calibration matrices for the 12 silhouette cameras are stored in the array calib – each matrix corresponds to a 3×4 linear transformation from 3D to 2D
then the voxel 3D coordinate arrays X,Y,Z and the associated occupancy grid, that shall be filled with 0 or 1, are defined
grid resolution can be modified with the parameter resolution (if you program is too slow, you can reduce the resolution)
training MLP to capture implicit representation
input: x,y,z
output: occupancy (0 or 1)
training based on the voxel representation
Segmentation – HourGlass vs. U-Net
HourGlass – autoencoder with convolutions and deconvolutions, has bottleneck
U-Net was invented to address precision problems of the original hourglass network
provides skip connections from intermediate representations